

Cookies Notice
This site uses cookies to deliver services and to analyze traffic.
As the number of open-source packages in package registries (e.g., npm/Maven) increases, detecting malicious packages is only becoming more challenging. The community is devoted to detecting and removing such malicious packages, ranging from focusing on detection through automated tools to preemptively halting publishing.
Despite the security community’s best efforts, malicious packages continue to spread, and those that go undetected pose a significant risk to organizations—causing harm as early as when they’re installed on a local machine during development.
To aid in the effort to identify malicious packages and uncover previously overlooked ones, Apiiro is dedicated to improving its code analysis capabilities by combining large language models (LLMs) with advanced pattern detection and self-enhancement techniques. This approach aims to make detection more scalable and improve coverage, catching malicious packages by learning from previous detections.
In this exciting era where LLMs and generative AI seem to solve all of our problems, it might be tempting to think that using GPT or another strong LLM to scan every piece of package code to determine its maliciousness (like this, for example) is a good idea. But this is completely infeasible because of the volume of files to scan in large codebases. To account for the scale that modern applications require, our solution relies on several detectors—algorithms that run very fast, providing indications or conclusions about whether a code is malicious.
At the core of our strategy is a brand new concept: LLM Code Patterns, or LCPs. LCPs are simplified representations of code transformed into vector format that capture the essence of the code, allowing detectors to draw similarities between different pieces of code more efficiently. LCPs are the product of our team’s intensive and comprehensive research with the sole goal of making malicious software detection more efficient and scalable.

In this post, we will focus on the LCP-based detector and how it improves itself based on both its own insights and the LLM-based detector’s insights.
To establish similarities and cluster packages, our LCP detector incorporates the following:
To make our LCP detector even more intelligent, we created a self-enhancing mechanism that assimilates and generalizes past detections, widening the detection coverage even more.
Since the LCP-based detector improves as it is introduced to new LCPs, we have incorporated an enhancer that analyzes and understands malicious packages with an LLM, extracts LCPs, and feeds them to a pattern enhancer to create an improved detector.

By repeating the process using all published packages, the detectors form a local space exploration and detect more undiscovered malicious variants.
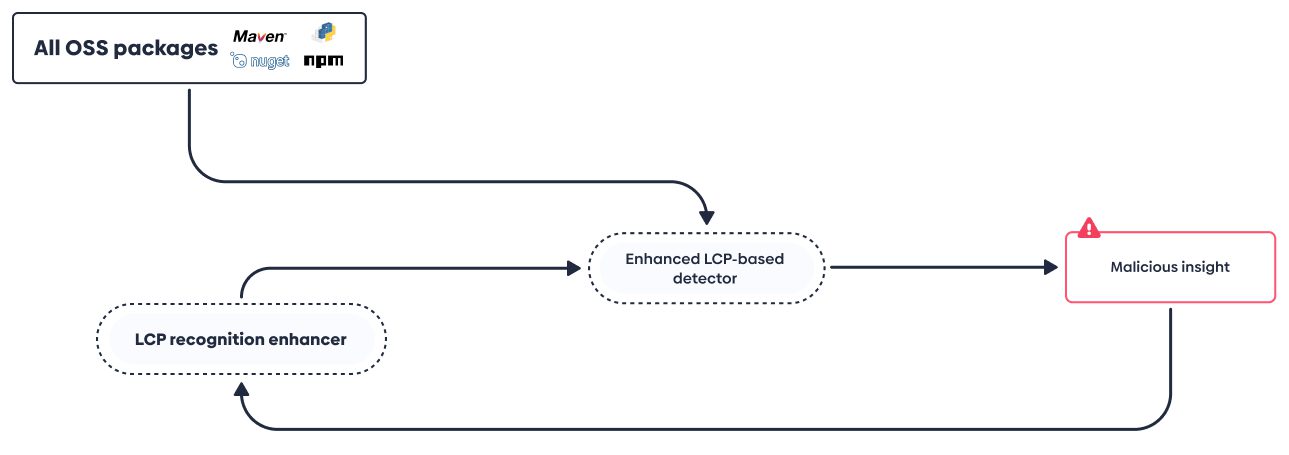
By using an LCP that expresses maliciousness, the mechanism identifies many new malicious packages. Coupled with input from other mechanisms, it also identifies old malicious packages that were previously overlooked, increasing the detection’s coverage and making package registries safer overall.
To find similarities between malicious packages based on LCPs, we use LCP’s vector representation in an n-dimensional space that captures code features and maliciousness. This allows us to track similar variants of newly-detected malicious packages and provide contextual alerts. Our approach has successfully identified similarities between packages based on malicious activity, uncovering previously undetected packages that share similar LCPs.
For example, our approach detected two malicious PyPI packages, easycordey (Dec 2022) and web3-checksum (April).

In the reduced dimensionality visualizations below, each point is a package.

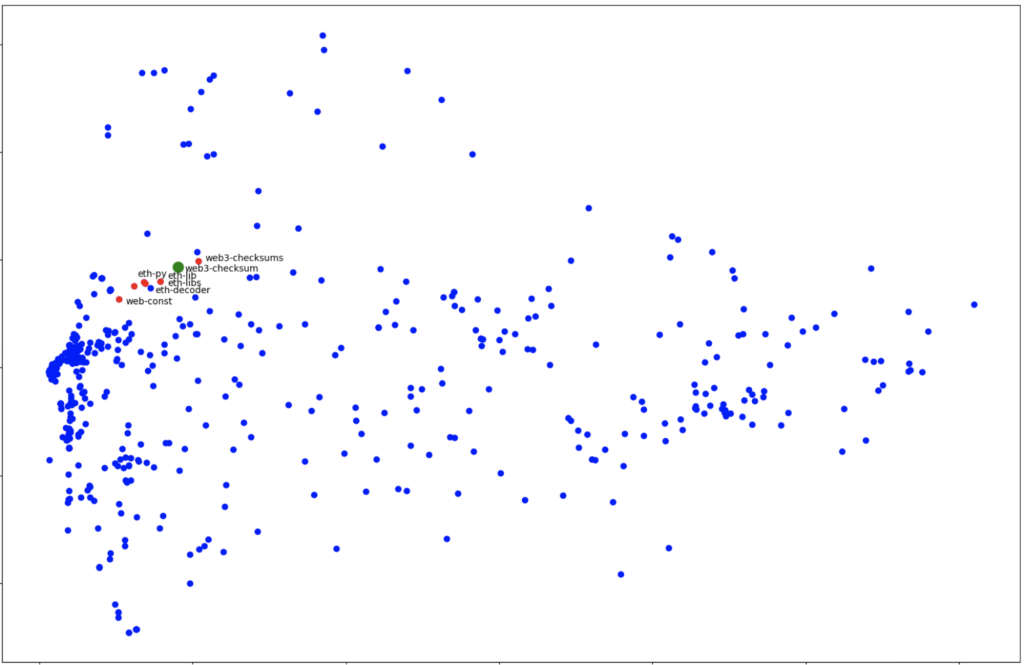
PyPI has been notified about all packages and removed them.
Our approach, which incorporates LLMs and self-enhancing LCP-based detectors, expands and strengthens the detection of previously overlooked malicious packages, contributing to a safer open source ecosystem.
Out of the box, Apiiro’s risk engine detects malicious packages identified based on the above mechanism. These packages will be reflected alongside other open source alerts in Apiiro with a “Malicious package” insight.
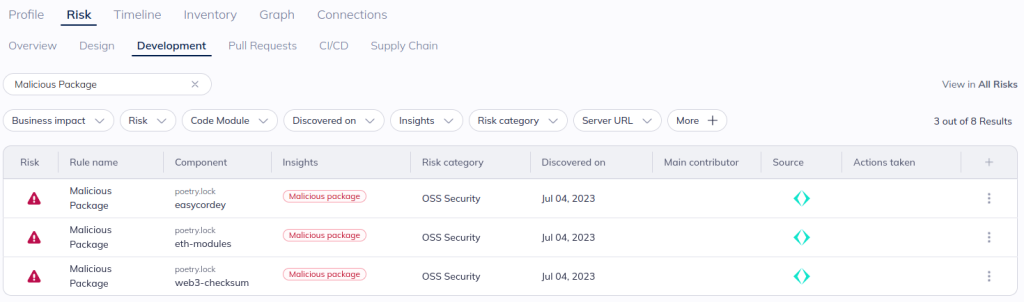
These insights—with additional context such as whether it is deployed to an internet-facing location or is part of a high-business impact application—can be used as criteria when building automated workflows to trigger notifications and developer guardrails and for internal governance.
At the end of the day, our goal is to enable organizations to automatically identify and address references to potentially harmful packages. To see this novel approach in action for your open-source packages, get in touch with our team. And stay tuned for additional posts on how we leverage LLMs to more efficiently secure modern applications.

This site uses cookies to deliver services and to analyze traffic.